前言
本篇博客记录北航计算机组成课程P3至P7的流水线CPU迭代以及相关思考题。
CPU设计文档
概述
本次通过Verilog设计流水线CPU架构支持了基本要求的指令指令。首先给出基本框架图:(内部转发实现后W到D级的转发不需要再实现)。以下是到P6为止的电路图(P7加了几个模块太懒了没画QAQ)。
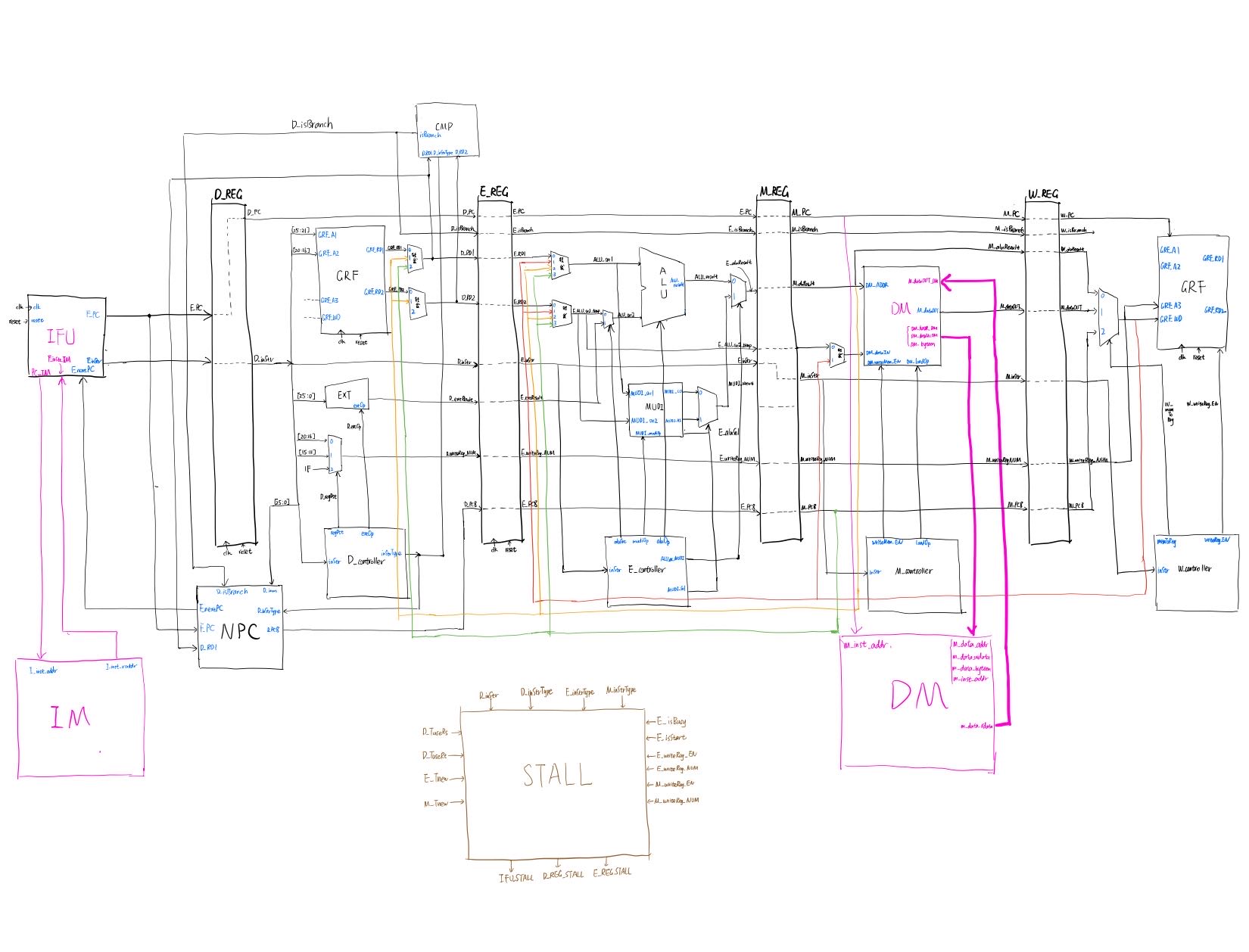
总电路图
P7总电路如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
| `include "InStrType.v"
`timescale 1ns / 1ps
module mips (
input clk,
input reset,
input interrupt,
output [31:0] macroscopic_pc,
output [31:0] i_inst_addr,
input [31:0] i_inst_rdata,
output [31:0] m_data_addr,
input [31:0] m_data_rdata,
output [31:0] m_data_wdata,
output [ 3:0] m_data_byteen,
output [31:0] m_int_addr,
output [ 3:0] m_int_byteen,
output [31:0] m_inst_addr,
output w_grf_we,
output [4:0] w_grf_addr,
output [31:0] w_grf_wdata,
output [31:0] w_inst_addr
);
wire [31:0] PrAddr, PrAddr_out, PrWD, PrWD_out, TC0_data, TC1_data, PrRD;
wire [31:0] single_pc;
wire [ 5:0] intReq;
wire [ 3:0] PrByteEn;
wire TC0_WE, TC1_WE;
wire TC0_req, TC1_req;
assign m_data_wdata = PrWD_out;
assign macroscopic_pc = single_pc;
assign m_int_addr = PrAddr_out;
assign m_data_addr = PrAddr_out;
assign intReq = {1'b0, 1'b0, 1'b0, interrupt, TC1_req, TC0_req};
CPU cpu (
.clk(clk),
.reset(reset),
.intReq(intReq),
.i_inst_rdata(i_inst_rdata),
.m_data_rdata(PrRD),
.i_inst_addr(i_inst_addr),
.m_data_addr(PrAddr),
.m_data_wdata(PrWD),
.m_data_byteen(PrByteEn),
.m_inst_addr(m_inst_addr),
.w_grf_we(w_grf_we),
.w_grf_addr(w_grf_addr),
.w_grf_wdata(w_grf_wdata),
.w_inst_addr(w_inst_addr),
.macro_PC(single_pc)
);
BRIDGE bridge (
.PrAddr(PrAddr),
.PrWD(PrWD),
.PrByteEn(PrByteEn),
.TC0_RD(TC0_data),
.TC1_RD(TC1_data),
.DM_RD(m_data_rdata),
.Int_RD(32'h0),
.PrRD(PrRD),
.IntByteEn_OUT(m_int_byteen),
.DMByteEn_OUT(m_data_byteen),
.TC0_WE(TC0_WE),
.TC1_WE(TC1_WE),
.PrWD_OUT(PrWD_out),
.PrAddr_OUT(PrAddr_out)
);
TC TC0 (
.clk(clk),
.reset(reset),
.Addr(PrAddr_out[31:2]),
.WE(TC0_WE),
.Din(PrWD_out),
.Dout(TC0_data),
.IRQ(TC0_req)
);
TC TC1 (
.clk(clk),
.reset(reset),
.Addr(PrAddr_out[31:2]),
.WE(TC1_WE),
.Din(PrWD_out),
.Dout(TC1_data),
.IRQ(TC1_req)
);
endmodule
|
数据通路模块
IFU(取指令单元)
模块内部包含PC(程序计数器)以及IM(指令存储器)。
端口定义
| 信号名 |
方向 |
位宽 |
描述 |
| clk |
I |
1 |
时钟信号 |
| reset |
I |
1 |
同步复位信号 |
| IFU_STALL |
I |
1 |
使能信号,用于暂停情况 |
| nextPC |
I |
32 |
下一条要被执行的指令的地址 |
| F_inStr_IM |
I |
32 |
外部 IM 传入的指令 |
| F_PC |
O |
32 |
输出当前正在执行的指令的地址 |
| F_inStr |
O |
32 |
输出当前正在执行的指令 |
| PC_IM |
O |
32 |
传至外部 IM 的PC值 |
GRF(通用寄存器组)
该模块内部包含 32 个具有写使能 32 位寄存器,分别对应 MIPS 架构中0~31通用寄存器(其中 0 号寄存器中的值恒为 0,即不具备写使能)。GRF 可以实现同步复位,同时可以根据输入的 5 位地址(0~31)向寄存器堆存取数据,实现定向访存寄存器。
端口定义
| 信号名 |
方向 |
位宽 |
描述 |
| PC |
I |
32 |
用于输出指定信息 |
| clk |
I |
1 |
时钟信号 |
| reset |
I |
1 |
同步复位信号 |
| GRF_A1 |
I |
5 |
将对应寄存器的数据读出到 GRF_RD1 |
| GRF_A2 |
I |
5 |
将对应寄存器的数据读出到 GRF_RD2 |
| GRF_A3 |
I |
5 |
写入目标寄存器的编号 |
| GRF_WD |
I |
32 |
数据输入信号 |
| W_writeReg_EN |
I |
1 |
写使能信号 |
| GRF_RD1 |
O |
32 |
输出 GRF_A1 指定的寄存器中的 32 位数据 |
| GRF_RD2 |
O |
32 |
输出 GRF_A2 指定的寄存器中的 32 位数据 |
NPC
负责计算下一条指令的地址并传递给PC。
| 信号名 |
方向 |
位宽 |
描述 |
| F_PC |
I |
32 |
当前指令地址 |
| D_RD1 |
I |
32 |
用于jr指令,传入地址 |
| D_imm |
I |
25 |
立即数来源 |
| D_isBranch |
I |
1 |
用于B类指令判断是否跳转 |
| D_inStrType |
I |
10 |
传递指令类型 |
| F_nextPC |
O |
32 |
输出下一指令地址 |
| D_PC8 |
O |
32 |
传递PC + 8,用于jal指令的转发 |
CMP
用于B级跳转指令的判断
| 信号名 |
方向 |
位宽 |
描述 |
| D_RD1 |
I |
32 |
参与比较的第一个值(转发后) |
| D_RD2 |
I |
32 |
参与比较的第二个值(转发后) |
| D_inStrType |
I |
10 |
D级指令类型 |
| isBranch |
O |
32 |
输出结果至NPC |
EXT
位扩展模块。
| 信号名 |
方向 |
位宽 |
描述 |
| EXT_imm |
I |
26 |
包含需要位扩展的立即数 |
| EXT_extOp |
I |
2 |
位扩展方式 |
| D_extResult |
O |
32 |
位扩展结果 |
ALU
该模块主要实现了加法、减法、按位或、立即数加载至高位(LUI)运算。
端口定义
| 信号名 |
方向 |
位宽 |
描述 |
| aluOp |
I |
3 |
ALU 功能选择信号 |
| ALU_src1 |
I |
32 |
参与 ALU 计算的第一个值 |
| ALU_src2 |
I |
32 |
参与 ALU 计算的第二个值 |
| ALU_result |
O |
32 |
输出 ALU 计算结果 |
MUDI(乘除模块)
| 信号名 |
方向 |
位宽 |
描述 |
| clk |
I |
1 |
时钟信号 |
| reset |
I |
1 |
同步复位信号 |
| E_isStart |
I |
1 |
乘除计算指令开始信号 |
| MUDI_mudiOp |
I |
3 |
MUDI 功能选择信号 |
| MUDI_src1 |
I |
32 |
参与 MUDI 计算的第一个值 |
| MUDI_src2 |
I |
32 |
参与 MUDI 计算的第二个值 |
| isBusy |
O |
1 |
MUDI 计算判断信号 |
| MUDI_HI |
O |
32 |
HI 寄存器值 |
| MUDI_LO |
O |
32 |
LO 寄存器值 |
DM(数据存储器)
该模块主要通过RAM实现,具有读写功能以及同步复位功能。
端口定义
| 信号名 |
方向 |
位宽 |
描述 |
| DM_writeMem_EN |
I |
1 |
写使能信号 |
| M_inStrType |
I |
10 |
M 级指令类型 |
| DM_ADDR |
I |
32 |
传入存取数据的地址 |
| DM_dataIN |
I |
32 |
传入待存储的数据 |
| M_dataOUT_DM |
I |
32 |
从外部 DM 传入的数据 |
| M_dataOUT |
O |
32 |
输出 M_dataOUT_DM 的数据 |
| DM_ADDR_DM |
O |
32 |
向外部 DM 传入地址 |
| DM_dataIN_DM |
O |
32 |
向外部 DM 传入数据 |
| DM_byteen_DM |
O |
32 |
向外部 DM 传入写使能信号 |
Controller(控制模块)
在控制模块中,我们对指令中 Opcode 域和 Funct 域中的数据进行解码,输出 ALUOp,MemtoReg 等10条控制指令,从而对数据通路进行调整,满足不同指令的需求。同时输出指令相关的Tuse和Tnew,便于流水。为实现该模块,我们又在内部设计了两部分 —— 和逻辑(AND Logic)和或逻辑(OR Logic)。前者的功能是识别,从输入的整条指令提取 Opcode 和 Funct ,从而识别为对应的指令,后者的功能是生成,根据输入指令的不同产生不同的控制信号。在每级流水线(D、E、M、W)设置不同的controller便于管理。
控制信号
| 序号 |
信号名 |
位宽 |
描述 |
| 1 |
inStrType |
10 |
传递指令信息 |
| 2 |
regDst |
2 |
GRF 中 A3 接口输入数据选择 |
| 3 |
aluSrc |
1 |
ALU_src2 接口输入数据选择 |
| 4 |
writeMem_EN |
1 |
DM 写入使能信号 |
| 5 |
memToReg |
1 |
GRF 中 WD 接口输入数据选择 |
| 6 |
writeReg_EN |
1 |
GRF 写入使能信号 |
| 7 |
aluOp |
3 |
ALU 功能选择信号 |
| 8 |
mudiOp |
3 |
MUDI 功能选择信号 |
| 9 |
extOp |
2 |
立即数符号扩展选择 |
| 10 |
MUDI_sel |
1 |
HI, LO 寄存器选择 |
| 11 |
ALU_or_MUDI |
1 |
ALU, MUDI 结果选择 |
| 12 |
isStart |
1 |
乘除有关指令开始信号 |
| 13 |
D_TuseRs |
2 |
判断指令对rs的使用时间 |
| 14 |
D_TuseRt |
2 |
判断指令对rt的使用时间 |
| 15 |
E_Tnew |
2 |
判断指令产生新值与E级距离 |
| 16 |
M_Tnew |
2 |
判断指令产生新值与M级距离 |
STALL(暂停控制器)
暂停模块通过比较Tuse与Tnew的关系,并且在D、E级以及IFU中通过控制使能信号实现在听操作,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| assign D_rs = D_inStr[25:21];
assign D_rt = D_inStr[20:16];
assign E_Stall_RS = (E_writeReg_NUM == D_rs && D_rs != 0) && (D_TuseRs < E_Tnew) && E_writeReg_EN;
assign E_Stall_RT = (E_writeReg_NUM == D_rt && D_rt != 0) && (D_TuseRt < E_Tnew) && E_writeReg_EN;
assign M_Stall_RS = (M_writeReg_NUM == D_rs && D_rs != 0) && (D_TuseRs < M_Tnew) && M_writeReg_EN;
assign M_Stall_RT = (M_writeReg_NUM == D_rt && D_rt != 0) && (D_TuseRt < M_Tnew) && M_writeReg_EN;
assign Stall_MUDI = E_start || E_busy;
assign isStall = E_Stall_RS | E_Stall_RT | M_Stall_RS | M_Stall_RT | Stall_MUDI;
assign IFU_STALL = isStall;
assign D_REG_STALL = isStall;
assign E_REG_STALL = isStall;
|
流水级寄存器
为满足流水线的需要,设置了四个流水级寄存器,分别是D_REG、E_REG、M_REG、W_REG。每级寄存器保存跨越不同流水级的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| module D_REG (
input clk,
input reset,
input D_REG_STALL,
input [31:0] F_PC,
input [31:0] F_inStr,
output [31:0] D_PC,
output [31:0] D_inStr
);
module E_REG (
input clk,
input reset,
input E_REG_STALL,
input [31:0] D_PC,
input [31:0] D_inStr,
input [31:0] D_PC8,
input [4:0] D_writeReg_NUM,
input [31:0] D_RD1,
input [31:0] D_RD2,
input [31:0] D_extResult,
input D_isBranch,
output [31:0] E_PC,
output [31:0] E_inStr,
output [31:0] E_PC8,
output [4:0] E_writeReg_NUM,
output [31:0] E_RD1,
output [31:0] E_RD2,
output [31:0] E_extResult,
output E_isBranch
);
module M_REG (
input clk,
input reset,
input [31:0] E_PC,
input [31:0] E_inStr,
input [31:0] E_PC8,
input [4:0] E_writeReg_NUM,
input [31:0] E_aluResult,
input [31:0] E_ALU_src2_temp,
input E_isBranch,
output [31:0] M_PC,
output [31:0] M_inStr,
output [31:0] M_PC8,
output [4:0] M_writeReg_NUM,
output [31:0] M_aluResult,
output [31:0] M_ALU_src2_temp,
output M_isBranch
);
module W_REG (
input clk,
input reset,
input [31:0] M_PC,
input [31:0] M_inStr,
input [31:0] M_PC8,
input [4:0] M_writeReg_NUM,
input [31:0] M_dataOUT,
input [31:0] M_aluResult,
input M_isBranch,
output [31:0] W_PC,
output [31:0] W_inStr,
output [31:0] W_PC8,
output [4:0] W_writeReg_NUM,
output [31:0] W_dataOUT,
output [31:0] W_aluResult,
output W_isBranch
);
|
转发的实现
本次设计主要由MUX实现转发,具体为在mips.v中通过assign语句以及三目运算符进行转发判断:
1
2
3
4
5
6
7
8
9
10
| assign D_RD1 = (M_inStrType == `jal && D_inStr[25:21] == 5'b11111) ? M_PC8 : (M_writeReg_NUM == D_inStr[25:21] && D_inStr[25:21] != 0 && M_writeReg_EN) ? M_aluResult : GRF_RD1;
assign D_RD2 = (M_inStrType == `jal && D_inStr[20:16] == 5'b11111) ? M_PC8 : (M_writeReg_NUM == D_inStr[20:16] && D_inStr[20:16] != 0 && M_writeReg_EN) ? M_aluResult : GRF_RD2;
assign ALU_src1 = (M_inStrType == `jal && E_inStr[25:21] == 5'b11111) ? M_PC8 : (M_writeReg_NUM == E_inStr[25:21] && E_inStr[25:21] != 0 && M_writeReg_EN) ? M_aluResult : (W_writeReg_NUM == E_inStr[25:21] && E_inStr[25:21] != 0 && W_writeReg_EN) ? W_writeReg_DATA : E_RD1;
assign E_ALU_src2_temp = (M_inStrType == `jal && E_inStr[20:16] == 5'b11111) ? M_PC8 : (M_writeReg_NUM == E_inStr[20:16] && E_inStr[20:16] != 0 && M_writeReg_EN) ? M_aluResult : (W_writeReg_NUM == E_inStr[20:16] && E_inStr[20:16] != 0 && W_writeReg_EN) ? W_writeReg_DATA : E_RD2;
assign DM_dataIN = (W_writeReg_NUM == M_inStr[20:16] && M_inStr[20:16] != 0 && W_writeReg_EN) ? W_writeReg_DATA : M_ALU_src2_temp;
|
思考题
1:上面我们介绍了通过 FSM 理解单周期 CPU 的基本方法。请大家指出单周期 CPU 所用到的模块中,哪些发挥状态存储功能,哪些发挥状态转移功能。
答:状态存储:IFU、GRF、DM;状态转移:NPC、Controller、ALU、EXT。
2:现在我们的模块中 IM 使用 ROM, DM 使用 RAM, GRF 使用 Register,这种做法合理吗? 请给出分析,若有改进意见也请一并给出。
答:我认为是合理的。ROM为只读寄存器,与IM的特性相同;RAM为读写寄存器且带有异步复位功能,与DM特性相同;GRF寄存器堆刚好可以使用Register实现。
3:在上述提示的模块之外,你是否在实际实现时设计了其他的模块?如果是的话,请给出介绍和设计的思路。
答:我还设计了NPC模块,将有关PC的计算部分独立出来作为一个模块。
4:事实上,实现 nop 空指令,我们并不需要将它加入控制信号真值表,为什么?
答:空指令到来后,控制信号均为假,已实现不进行任何操作的目的,所以不需要额外加入控制信号真值表。
5:阅读 Pre 的 “MIPS 指令集及汇编语言” 一节中给出的测试样例,评价其强度(可从各个指令的覆盖情况,单一指令各种行为的覆盖情况等方面分析),并指出具体的不足之处。
答:我认为测试样例覆盖率较好,但是数据范围较小,且未设计$0寄存器的测试。并且未测试sub指令。
1. 阅读下面给出的 DM 的输入示例中(示例 DM 容量为 4KB,即 32bit × 1024字),根据你的理解回答,这个 addr 信号又是从哪里来的?地址信号 addr 位数为什么是 [11:2] 而不是 [9:0] ?

思考题
答:Addr由ALU的计算结果得出,由于1个字占4个字节,所以Addr后两位恒为0,为了节省空间从而取[11:2]。
2. 思考上述两种控制器设计的译码方式,给出代码示例,并尝试对比各方式的优劣。
指令对应的信号如何取值,如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| case(instruction_type)
0: begin
MemWrite <= 0;
ctrl_skip_type <= 0;
RegWrite <= 0;
end
1: begin
MemtoReg <= 1;
MemWrite <= 0;
ctrl_skip_type <= 0;
ALUCtrl <= 1;
ALUSrc <= 0;
RegDst <= 1;
RegWrite <= 1;
issigned_extend <= 0;
end
// ...
|
控制信号每种取值所对应的指令,如:
1
2
3
4
5
6
7
8
| assign memToReg[0] = lw | lb;
assign memToReg[1] = jal;
assign memWrite = sw | sb;
assign regDst[0] = add | sub;
assign regDst[1] = jal;
assign aluOp[0] = add | lui | lw | sw | lb | sb;
assign aluOp[1] = ori | lui;
// ...
|
前者的优势是在设计时思路较为清晰,后者的优势是代码便于理解,修改或调试时更加方便。
3:在相应的部件中,复位信号的设计都是同步复位,这与 P3 中的设计要求不同。请对比同步复位与异步复位这两种方式的 reset 信号与 clk 信号优先级的关系。
答:同步复位时clk信号优先级高于reset信号,只有clk上升沿到来时reseti信号有效才会复位;异步复位时reset信号优先级高于clk信号,无论clk信号为何值,只要reset信号有效就会复位。
4:C 语言是一种弱类型程序设计语言。C 语言中不对计算结果溢出进行处理,这意味着 C 语言要求程序员必须很清楚计算结果是否会导致溢出。因此,如果仅仅支持 C 语言,MIPS 指令的所有计算指令均可以忽略溢出。 请说明为什么在忽略溢出的前提下,addi 与 addiu 是等价的,add 与 addu 是等价的。提示:阅读《MIPS32® Architecture For Programmers Volume II: The MIPS32® Instruction Set》中相关指令的 Operation 部分。
答:在忽略溢出的前提下,add与addi均不需要考虑对于溢出的判断,且保存结果的后32位,从而与addu、addiu等价。
1:我们使用提前分支判断的方法尽早产生结果来减少因不确定而带来的开销,但实际上这种方法并非总能提高效率,请从流水线冒险的角度思考其原因并给出一个指令序列的例子。
答:提前的分支判断会使TuseRt、TuseRs的值提前发生变化,从而影响暂停控制器对于是否需要暂停的判断:比如
1
2
| add $t0, $t1, $t2
beq $t0, $s0, label
|
若判断提前至D级,则需要暂停使得beq中$t0为计算后的新值,而不提前则不需要暂停。
2:因为延迟槽的存在,对于 jal 等需要将指令地址写入寄存器的指令,要写回 PC + 8,请思考为什么这样设计?
答:若考虑延迟槽,则PC+4指令在当前jal指令进入D级时已经取出并进入流水线,在返回时要从PC+8开始执行,否则PC+4会执行两次,导致程序错误。
3:我们要求大家所有转发数据都来源于流水寄存器而不能是功能部件(如 DM 、 ALU ),请思考为什么?
答:如果从功能部件进行转发,则会增长关键路径长度,其会使时钟频率变长,降低效率。
4:我们为什么要使用 GPR 内部转发?该如何实现?
答:GRF的内部转发等价于W级数据转发至D级,若不实现内部转发,则位于D级的指令要使用W级写入的数据时,输出的是旧数据而非新数据。(读写在上升沿同时发生,所以读出的是新写入前的数据)。实现方法如下,只需在GRF对输出进行修改:
1
2
| assign GRF_RD1 = (GRF_A3 && W_writeReg_EN && GRF_A3 == GRF_A1) ? GRF_WD : register[GRF_A1];
assign GRF_RD2 = (GRF_A3 && W_writeReg_EN && GRF_A3 == GRF_A2) ? GRF_WD : register[GRF_A2];
|
5:我们转发时数据的需求者和供给者可能来源于哪些位置?共有哪些转发数据通路?
答:如图所示,黄线、红线、绿线起点为供给者,终点为需求者。
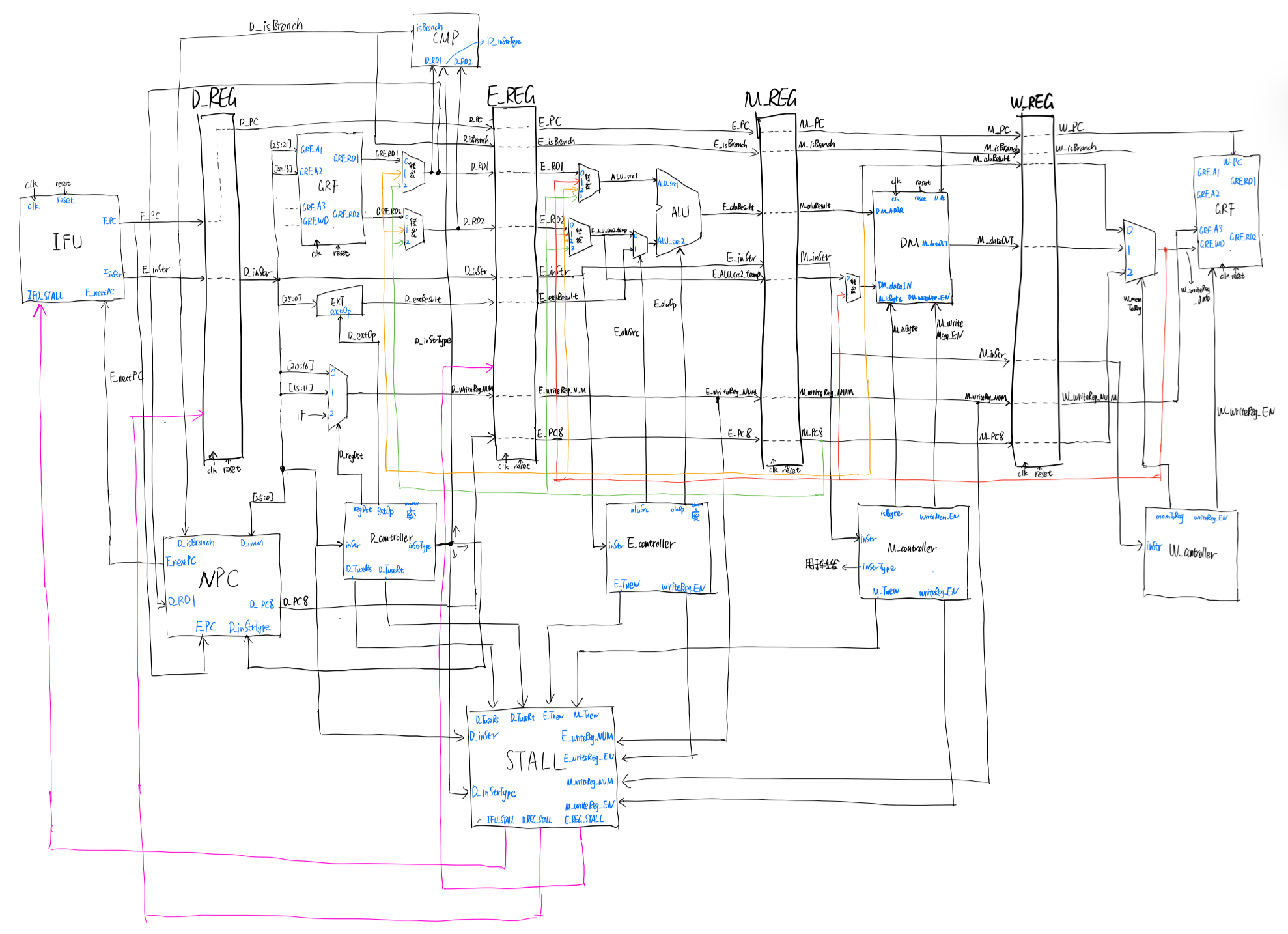
总电路图
6:在课上测试时,我们需要你现场实现新的指令,对于这些新的指令,你可能需要在原有的数据通路上做哪些扩展或修改?提示:你可以对指令进行分类,思考每一类指令可能修改或扩展哪些位置。
答:可能需要增加控制信号,增加流水级寄存器的传递值以及增加ALU、NPC的计算方法。
7:确定你的译码方式,简要描述你的译码器架构,并思考该架构的优势以及不足。
答:译码器结构分为两部分,判断指令类型以及输出控制信号:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| wire rType, nop, add, sub, jr, ori, lw, sw, beq, lui, jal;
assign nop = (opcode == 6'b000000) & (funct == 6'b000000);
assign rType = (opcode == `RTYPE);
assign add = rType & (funct == `ADD);
assign sub = rType & (funct == `SUB);
assign jr = rType & (funct == `JR);
assign ori = opcode == `ORI;
assign lw = opcode == `LW;
assign sw = opcode == `SW;
assign beq = opcode == `BEQ;
assign lui = opcode == `LUI;
assign jal = opcode == `JAL;
assign lb = opcode == `LB;
assign sb = opcode == `SB;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
assign inStrType = nop ? `nop : add ? `add : sub ? `sub :
jr ? `jr : ori ? `ori : lw ? `lw : sw ? `sw :
beq ? `beq : lui ? `lui : jal ? `jal :
lb ? `lb : sb ? `sb : `nop;
assign regDst[0] = add | sub;
assign regDst[1] = jal;
assign aluSrC = lw | sw | lb | sb | ori | lui;
assign memWrite_EN = sw | sb;
assign memToReg[0] = lw | lb;
assign memToReg[1] = jal;
assign regWrite_EN = add | sub | ori | lui | lw | lb | jal;
assign aluOp[0] = add | lui | lw | sw | lb | sb;
assign aluOp[1] = ori | lui;
assign aluOp[2] = 0;
assign extOp[0] = lw | sw | lb | sb | beq;
assign extOp[1] = 0;
assign isByte = lb | sb;
assign D_TuseRs[0] = add | sub | ori | lw | lb | sw | sb | nop | lui | jal;
assign D_TuseRs[1] = nop | lui | jal;
assign D_TuseRt[0] = add | sub | nop | lui | jal | ori | lw | lb | jr;
assign D_TuseRt[1] = sw | sb | nop | lui | jal | ori | lw | lb | jr;
assign E_Tnew[0] = add | sub | ori | lui;
assign E_Tnew[1] = lw | lb;
assign M_Tnew[0] = lw | lb;
assign M_Tnew[1] = 0;
|
优点在于代码整体直观简洁,且便于修改。
1:为什么需要有单独的乘除法部件而不是整合进 ALU?为何需要有独立的 HI、LO 寄存器?
答:乘除相关的指令涉及到时序逻辑,而ALU的功能目前仅涉及到组合逻辑,所以乘除相关指令更适合放到单独的模块中。如果不使用独立的HI、LO寄存器,即在GRF中添加HI、LO寄存器,那么mfhi、mflo、mthi、mtlo等指令关于HI、LO寄存器的操作会变得混乱,会与通用寄存器的写入、读取操作混淆。
2:真实的流水线 CPU 是如何使用实现乘除法的?请查阅相关资料进行简单说明。
答:CPU执行乘法指令是以加法为基础进行的,乘法的本质是若干个相同的数相加。CPU执行除法指令是以减法为基础的,减法也是以加法为基础的,除法的本质是看被除数能够减去除数几次,这个“几次”便是得到的商,减去若干次后剩下的不够再减一次的部分便是余数。
3:请结合自己的实现分析,你是如何处理 Busy 信号带来的周期阻塞的?
答:在暂停模块中加入对MUDI模块有关的Start信号和Busy信号的考虑,当二者有一个有效时,则触发暂停。
4:请问采用字节使能信号的方式处理写指令有什么好处?(提示:从清晰性、统一性等角度考虑)
答:字节使能信号一方面保证了数据传输之间的一致性,即所有存取指令向DM传输的、从DM传来的地址和数据都是32位,另一方面也使存取的具体操作变得更加清晰。
5:请思考,我们在按字节读和按字节写时,实际从 DM 获得的数据和向 DM 写入的数据是否是一字节?在什么情况下我们按字节读和按字节写的效率会高于按字读和按字写呢?
答:不是,写入和读出的数据为32位。当按字节对数据进行处理的指令较多时按字节读写会有更高的效率。
6:为对抗复杂性你采取了哪些抽象和规范手段?这些手段在译码和处理数据冲突的时候有什么样的特点与帮助?
答:将乘除模块的计算结果与ALU的计算结果在E级通过多路选择器并到一起,这样p6的转发操作与p5完全相同不用修改。
7:在本实验中你遇到了哪些不同指令类型组合产生的冲突?你又是如何解决的?相应的测试样例是什么样的?
答:新的冒险冲突主要是针对乘除运算器和寄存器的使用争夺问题。1.乘除寄存器在运算时末能产生相应的HI和LO时需要执行mfio/mfhi/mtlo/mthi指令,这时直接阻塞即可。2.mtlo/mthi指令需要利用的Rs寄存器的最新的值可能还未产生,此时利用P5就构建好的转发路径即可。3.mflo/mfhi指令改变了寄存器的值.若有之后的指令需要使用相同寄存器时,同理进行转发即可。
8:如果你是手动构造的样例,请说明构造策略,说明你的测试程序如何保证覆盖了所有需要测试的情况;如果你是完全随机生成的测试样例,请思考完全随机的测试程序有何不足之处;如果你在生成测试样例时采用了特殊的策略,比如构造连续数据冒险序列,请你描述一下你使用的策略如何结合了随机性达到强测的效果。
答:首先给每个寄存器赋上不同的随机初值,再对其进行生成不同的操作。完全随机代码的缺点就是可能难以覆盖所有的矛盾冲突,因此我特意手动构造了一些关于冲突的指令,对于这些冲突的构造也是主要针对第7个思考题中提及的矛盾。
1.请查阅相关资料,说明鼠标和键盘的输入信号是如何被 CPU 知晓的?
鼠标和键盘相当于中断发生器,当鼠标和键盘产生输入信号时,其值会被写入相关寄存器,中断发生器将会给cpu一个中断信号,cpu收到中断信号后进入到异常处理程序中,在异常处理程序中获得键鼠的信息。
2.请思考为什么我们的 CPU 处理中断异常必须是已经指定好的地址?如果你的 CPU 支持用户自定义入口地址,即处理中断异常的程序由用户提供,其还能提供我们所希望的功能吗?如果可以,请说明这样可能会出现什么问题?否则举例说明。(假设用户提供的中断处理程序合法)
一种思路是,假如我们的cpu让用户定义入口地址,则可能需要我们新开辟输入端口令cpu输入地址,当用户键入地址时就需要中断来处理,但是此时还用户输入的地址还并未被知晓因此便无法得知从何处进入中断处理程序。而且我们指定入口地址的话,将无需软件工程师再费心从何处进入异常,而只需要编写自己所需要的异常处理程序即可,因此,这会大大降低软件工程师的压力。
3.为何与外设通信需要 Bridge?
因为如果不用桥而直接让cpu与外界设备进行通信,则cpu的端口就会变得很多(原本需要在桥上开的端口都将开到cpu上)这样会大大增加cpu的复杂度,而使用bridge就会让端口变得十分简洁。
4.请阅读官方提供的定时器源代码,阐述两种中断模式的异同,并针对每一种模式绘制状态移图。
模式0和模式1的相同点在于他们都需要“手动”开启计数使能而开始计数而不能自动开始计数,而他们的区别主要体现在:当计时器计时结束时,模式1下的计数器会自动将初值加载到计数器重新开始倒计数;在模式0下的计数器会停止计数并将计数器的计数使能关闭而停止倒计数,当计数使能被设置为1后再次开始计数。
5. 倘若中断信号流入的时候,在检测宏观 PC 的一级如果是一条空泡(你的 CPU 该级所有信息均为空)指令,此时会发生什么问题?在此例基础上请思考:在 P7 中,清空流水线产生的空泡指令应该保留原指令的哪些信息?
这时如果这个空泡是一个延迟槽指令的话,应该向cp0的epc中写入该pc-4,但是由于空泡指令不包含任何信息,这导致会写入到epc一个错误的值,同时不包含isBD这一信息的话,也无法判断该空泡处是否本应是一个延迟槽指令。因此,清空流水线所产生的空泡指令应该保留pc和isBD两个信息。
6. 为什么 jalr 指令为什么不能写成 jalr $31, $31?
当jalr或jalr的延迟槽异常时需要进入异常处理程序,处理完后需要跳回jalr重新执行,此时$31的值已被改变,使得程序运行出错。






