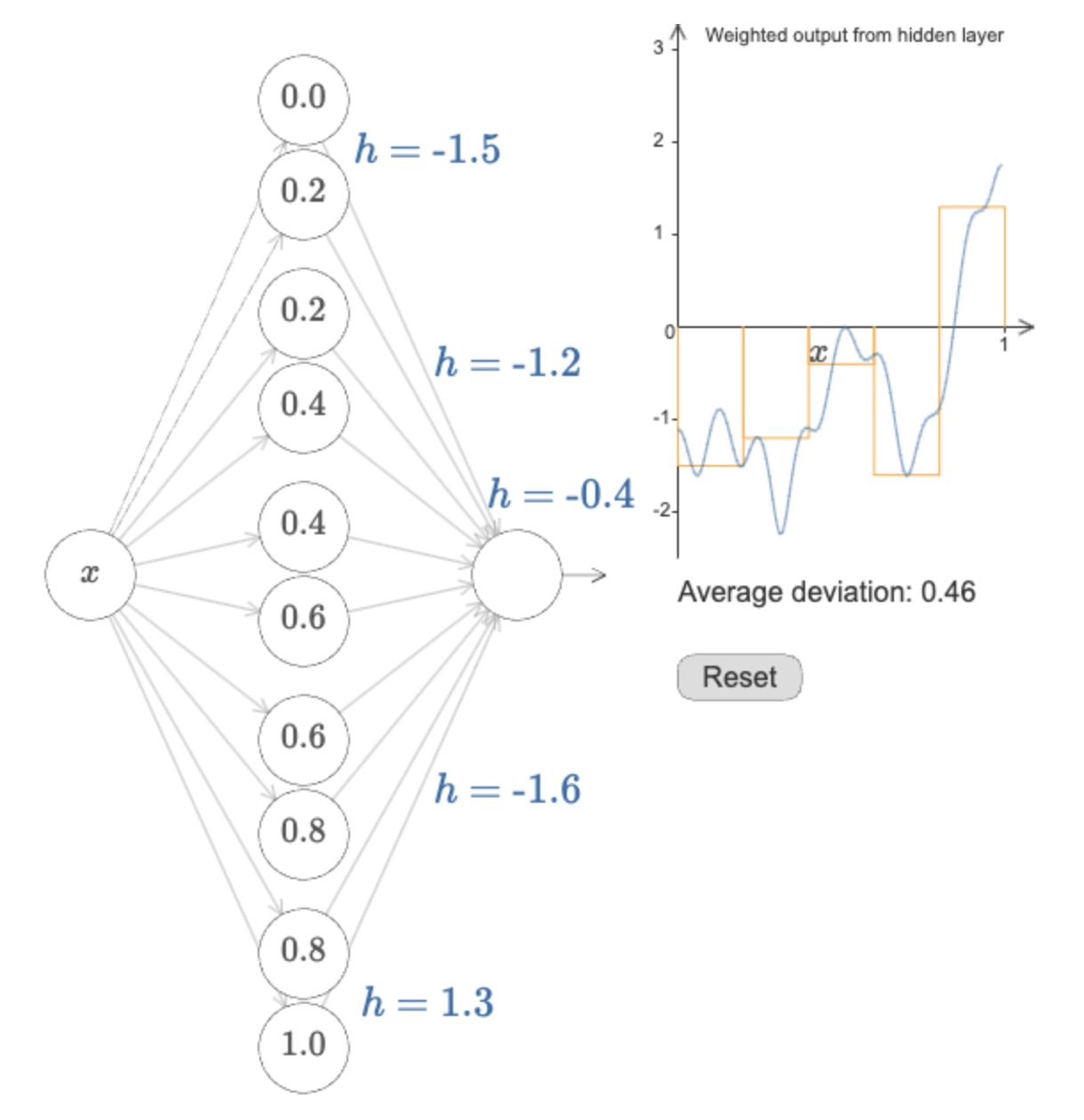
defbackprop(self, x, y): """Return a tuple ``(nabla_b, nabla_w)`` representing the gradient for the cost function C_x. ``nabla_b`` and ``nabla_w`` are layer-by-layer lists of numpy arrays, similar to ``self.biases`` and ``self.weights``.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w inzip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass delta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. for l inrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w)
deflarge_weight_initializer(self): """Initialize the weights using a Gaussian distribution with mean 0 and standard deviation 1. Initialize the biases using a Gaussian distribution with mean 0 and standard deviation 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers. This weight and bias initializer uses the same approach as in Chapter 1, and is included for purposes of comparison. It will usually be better to use the default weight initializer instead. """ self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x) for x, y inzip(self.sizes[:-1], self.sizes[1:])] defdefault_weight_initializer(self): """Initialize each weight using a Gaussian distribution with mean 0 and standard deviation 1 over the square root of the number of weights connecting to the same neuron. Initialize the biases using a Gaussian distribution with mean 0 and standard deviation 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers. """ self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x)/np.sqrt(x) for x, y inzip(self.sizes[:-1], self.sizes[1:])]
classNetwork(object): def__init__(self, layers, mini_batch_size): """Takes a list of `layers`, describing the network architecture, and a value for the `mini_batch_size` to be used during training by stochastic gradient descent. """ self.layers = layers self.mini_batch_size = mini_batch_size self.params = [param for layer in self.layers for param in layer.params] self.x = T.matrix("x") self.y = T.ivector("y") init_layer = self.layers[0] init_layer.set_inpt(self.x, self.x, self.mini_batch_size) for j in xrange(1, len(self.layers)): prev_layer, layer = self.layers[j-1], self.layers[j] layer.set_inpt( prev_layer.output, prev_layer.output_dropout, self.mini_batch_size) self.output = self.layers[-1].output self.output_dropout = self.layers[-1].output_dropout
self.params = [param for layer in ...] 将每个层的参数收集到一个列表中。 Network.SGD() 方法将使用 self.params 来确定 Network 中的哪些变量可以学习。 self.x = T.matrix("x") 和 self.y = T.ivector("y") 行定义了名为 x 和 y 的 Theano 符号变量。这些将用于表示网络的输入和所需的输出。接下来的几行代码定义了网络的符号输出。我们首先使用init_layer.set_inpt(self.x, self.x, self.mini_batch_size)将输入设置为初始层,注意到函数两次传递输入 self.x :这是因为我们可能以两种不同的方式使用网络(带或不带 dropout)。然后, for 循环通过 Network 的各层向前传播符号变量 self.x 。这允许我们定义最终的 output 和 output_dropout 属性,它们表示 Network 的输出。
defSGD(self, training_data, epochs, mini_batch_size, eta, validation_data, test_data, lmbda=0.0): """Train the network using mini-batch stochastic gradient descent.""" training_x, training_y = training_data validation_x, validation_y = validation_data test_x, test_y = test_data
# compute number of minibatches for training, validation and testing num_training_batches = int(size(training_data)/mini_batch_size) num_validation_batches = int(size(validation_data)/mini_batch_size) num_test_batches = int(size(test_data)/mini_batch_size)
# define the (regularized) cost function, symbolic gradients, and updates l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers]) cost = self.layers[-1].cost(self)+\ 0.5*lmbda*l2_norm_squared/num_training_batches grads = T.grad(cost, self.params) updates = [(param, param-eta*grad) for param, grad inzip(self.params, grads)]
# define functions to train a mini-batch, and to compute the # accuracy in validation and test mini-batches. i = T.lscalar() # mini-batch index train_mb = theano.function( [i], cost, updates=updates, givens={ self.x: training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) validate_mb_accuracy = theano.function( [i], self.layers[-1].accuracy(self.y), givens={ self.x: validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) test_mb_accuracy = theano.function( [i], self.layers[-1].accuracy(self.y), givens={ self.x: test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size], self.y: test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) self.test_mb_predictions = theano.function( [i], self.layers[-1].y_out, givens={ self.x: test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size] }) # Do the actual training best_validation_accuracy = 0.0 for epoch inrange(epochs): for minibatch_index inrange(num_training_batches): iteration = num_training_batches*epoch+minibatch_index if iteration % 1000 == 0: print("Training mini-batch number {0}".format(iteration)) cost_ij = train_mb(minibatch_index) if (iteration+1) % num_training_batches == 0: validation_accuracy = np.mean( [validate_mb_accuracy(j) for j inrange(num_validation_batches)]) print("Epoch {0}: validation accuracy {1:.2%}".format( epoch, validation_accuracy)) if validation_accuracy >= best_validation_accuracy: print("This is the best validation accuracy to date.") best_validation_accuracy = validation_accuracy best_iteration = iteration if test_data: test_accuracy = np.mean( [test_mb_accuracy(j) for j inrange(num_test_batches)]) print('The corresponding test accuracy is {0:.2%}'.format( test_accuracy)) print("Finished training network.") print("Best validation accuracy of {0:.2%} obtained at iteration {1}".format( best_validation_accuracy, best_iteration)) print("Corresponding test accuracy of {0:.2%}".format(test_accuracy))
SGD()方法中包含初始化、正向传播、反向传播等方法。重点关注一下几行:
1 2 3 4 5 6 7 8 9 10 11 12 13
# define the (regularized) cost function, symbolic gradients, and updates l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers]) cost = self.layers[-1].cost(self)+\ 0.5*lmbda*l2_norm_squared/num_training_batches grads = T.grad(cost, self.params) updates = [(param, param-eta*grad) for param, grad inzip(self.params, grads)] ''' cost() ''' defcost(self, net): "Return the log-likelihood cost." return -T.mean(T.log(self.output_dropout)[T.arange(net.y.shape[0]), net.y])